Your Open-Source Intelligent Assistant
Introduction
2025 is the year of the Agent. AI capabilities have now reached human level in multiple domains and we will all have teams of agents at our fingertips to help us in our personal life, work and beyond.
As the agent swarm arrives, connected by MCP, A2A and other protocols, we believe that it is essential that these have at the core solid, open, transparent and auditable foundation. This is particularly true for the things that really matter - managing our health, teaching our kids, coordinating our financial system and more. These can integrate proprietary and expert systems to have the best of both worlds.
To this end, we are delighted today to introduce II-Agent, our open source agent framework that not only tops the benchmarks for available agents, but is also fully open source.
This is a component of the broader Intelligent Internet system we are building: datasets, models, agents, swarms and systems that will be fully open to tackle every regulated industry and enable maximum adoption and alignment.
We made II to increase the intelligence of humanity. We can’t wait to see what you build with II-Agent and our upcoming releases to contribute to this goal.
A Recent History of Autonomous Agents
In recent years, the rise of autonomous AI agents has signaled a significant leap in how we interact with technology—shifting from passive tools to intelligent systems capable of independently executing complex tasks. Among the most prominent developments are Manus and GenSpark AI, two cutting-edge closed-source agents that exemplify this evolution:
Manus [1] is an advanced autonomous AI agent developed by Monica (Butterfly Effect AI), a Chinese startup, officially introduced in March 2025. Designed to bridge human intent and task execution autonomously, Manus is capable of independently handling complex activities across various domains, including data analysis, content creation, coding, and personal assistance. With multi-modal functionality, it seamlessly processes and generates text, images, and code, integrating smoothly with tools like browsers, code editors, and databases to perform real-time tasks and workflow automation. Manus continuously adapts through user interactions, refining its approach to deliver increasingly personalized results. It achieved notable performance on the GAIA benchmark, scoring approximately 65%, and was claimed as state-of-the-art when it was released for the first time. It is applied effectively in business analytics, educational content generation, creative media, and personal organization.
GenSpark AI [2] is an innovative AI agent engine that reimagines traditional search by employing a multi-agent framework to generate custom, real-time "Sparkpages" tailored to user queries. Each AI agent within this system specializes in different types of information, contributing unique insights to create comprehensive, unbiased content. Unlike conventional search engines that direct users to existing web pages, GenSpark synthesizes information from various reputable sources, delivering synthesized results free from commercial influences or SEO-driven content. These Sparkpages are equipped with an AI copilot, facilitating dynamic user interaction and deeper exploration of topics. By minimizing the need to navigate multiple links and ads, GenSpark offers a cleaner, more informative, and efficient digital experience, revolutionizing how users access and interact with information online.
While these proprietary tools represent significant milestones, they also underscore the growing need for open-source alternatives that are transparent, extensible, and accessible to all. Several open-source efforts—such as OpenManus by Foundation Agent [8 ] and Suna by Kortix-AI [9] —have attempted to replicate the capabilities of Manus and GenSpark. However, none have come close to matching their performance or achieving comparable benchmark results.
In response, we are excited to introduce II-Agent—a generalist intelligent assistant designed to streamline and enhance workflows across multiple domains. Below is an overview of its core capabilities, including features and performance comparable to those offered by Manus and GenSpark:
Core Capabilities
II-Agent is a versatile open-source assistant built to elevate your productivity across domains. From research and content creation to data analysis, coding, automation, and problem solving, it adapts to your needs with intelligent, structured support. Dive into smarter workflows—and help shape the future of open, generalist AI.
Domain | What II‑Agent Can Do |
Research & Fact‑Checking | Multistep web search, source triangulation, structured note‑taking, rapid summarization |
Content Generation | Blog & article drafts, lesson plans, creative prose, technical manuals, Website creations |
Data Analysis & Visualization | Cleaning, statistics, trend detection, charting, and automated report generation |
Software Development | Code synthesis, refactoring, debugging, test‑writing, and step‑by‑step tutorials across multiple languages |
Workflow Automation | Script generation, browser automation, file management, process optimization |
Problem Solving | Decomposition, alternative‑path exploration, stepwise guidance, troubleshooting |
Example Outputs:
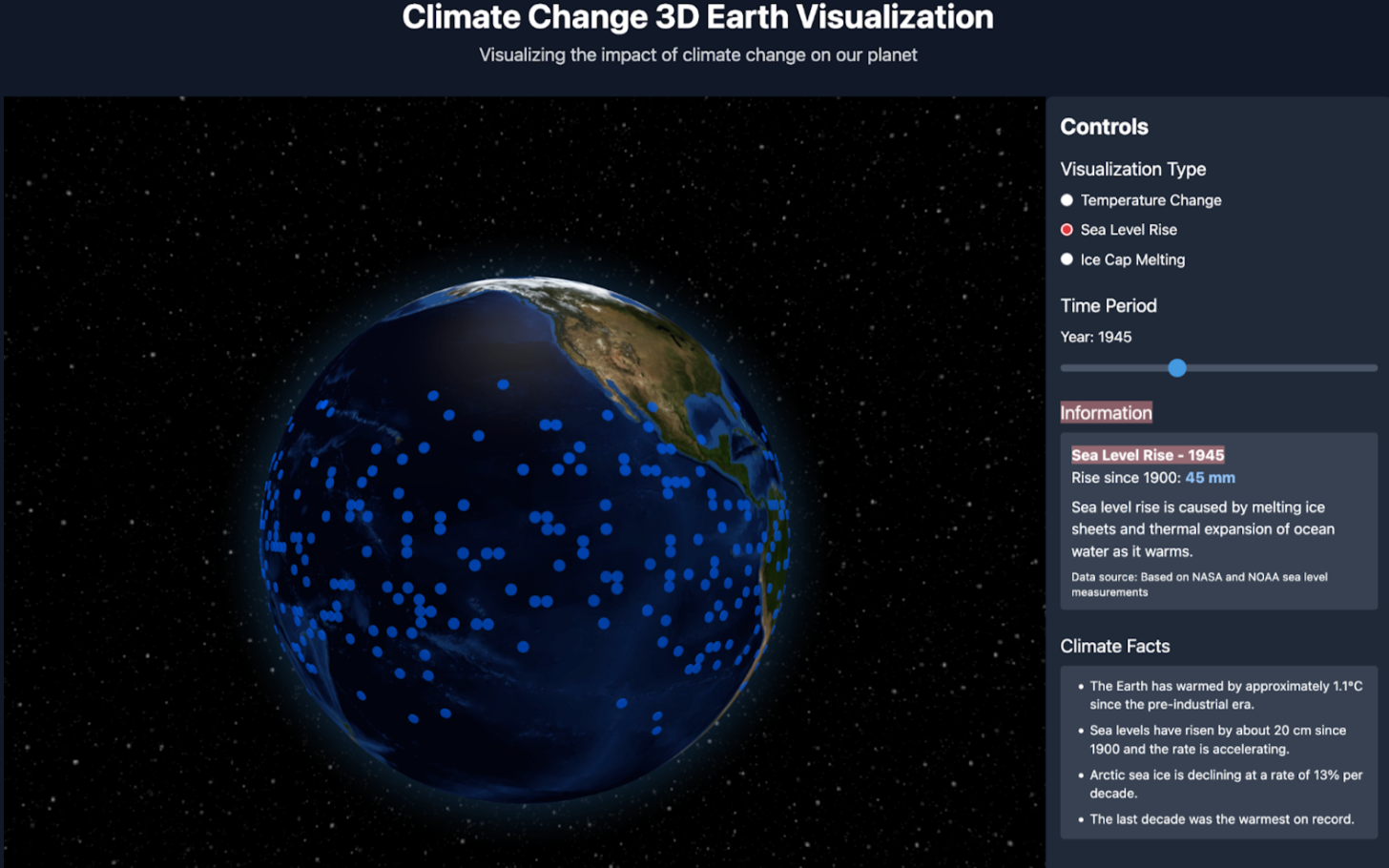
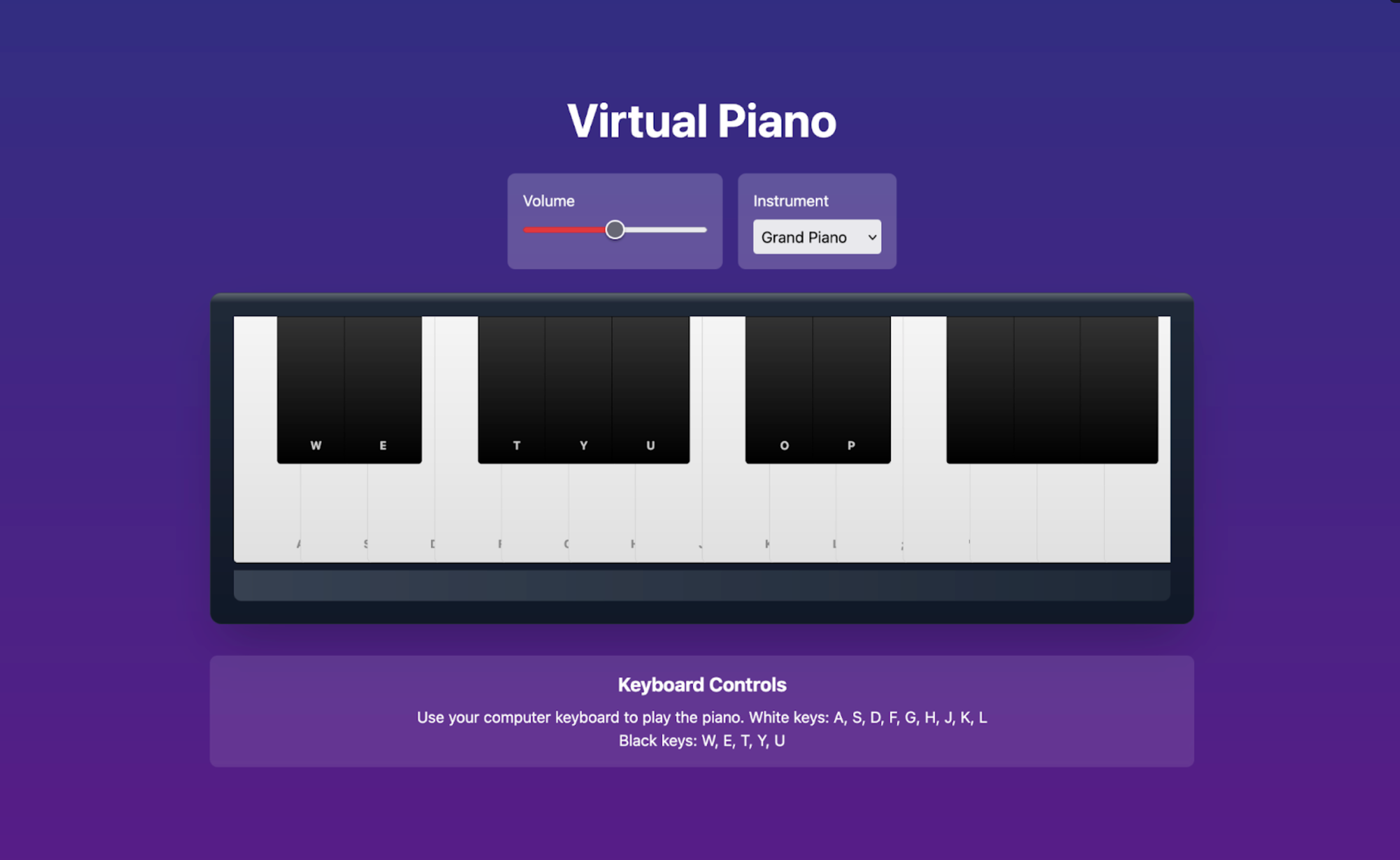
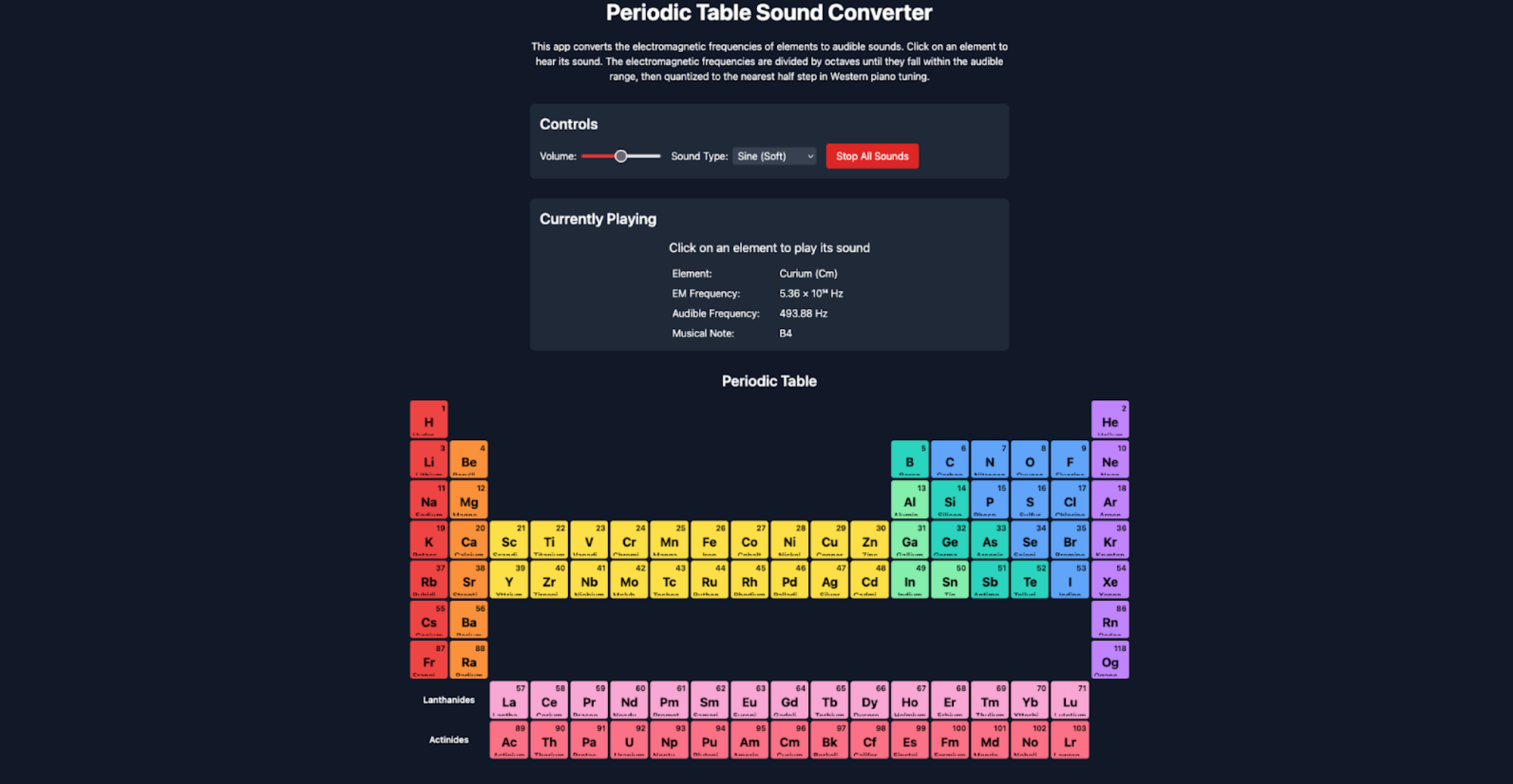


Methods
The II-Agent system represents a sophisticated approach to building versatile AI agents capable of tackling various tasks, from in-depth research and data analysis to software development and interactive content generation. Our methodology centers on a robust function-calling paradigm, driven by a powerful large language model (LLM), and supported by advanced planning, comprehensive execution capabilities, and intelligent context management. This design philosophy is informed by successful strategies observed in the field, such as using strong reasoning models like Anthropic's Claude 3.7 Sonnet for complex coding tasks [3].
1. Core Agent Architecture and LLM Interaction
The operational heart of II-Agent is a central reasoning and orchestration component that interfaces directly and optimally with a foundational LLM, specifically Anthropic's Claude 3.7 Sonnet. The agent's operational cycle is iterative and guided by several key principles:
- System Prompting: Each interaction cycle commences with the LLM receiving a comprehensive system prompt. This prompt is dynamically tailored to the current operational context, including information about the agent's workspace, the underlying operating system, and temporal data (e.g., the current date). Crucially, it defines the agent's persona, its repertoire of available capabilities, explicit rules for tool engagement (encompassing web browsing, shell command execution, file system operations, and software development), preferred linguistic styles, guidelines for content generation, error recovery protocols, and details of its sandboxed execution environment.
- Interaction History Management: A chronological record of the entire dialogue is meticulously maintained. This includes user-provided instructions, the agent's textual responses, any capabilities (tools) invoked by the agent, and the results observed from executing those capabilities. This history forms the primary contextual basis for the LLM's subsequent reasoning.
- Intelligent Context Management: A dedicated context management system analyzes the interaction history before each LLM invocation. This system estimates the token footprint of the current conversation and strategically applies truncation techniques if a predefined token budget (e.g., 120,000 tokens) is at risk of being exceeded. These techniques are designed to condense or summarize older parts of the conversation while prioritizing the full retention of the most recent and relevant exchanges.
- LLM Invocation and Capability Selection: The LLM is invoked with this curated conversational context, the overarching system prompt, and a dynamically updated manifest of currently available capabilities or "tools."
- Response Interpretation and Tool Execution: The LLM's output can manifest as a direct textual response to the user or, more commonly, as a directive to employ one or more available capabilities. Our current framework focuses on processing a single capability invocation per reasoning cycle to ensure methodical execution. When an ability is invoked, the agent identifies and executes the appropriate internal module responsible for that action. The outcomes of this execution are then systematically recorded back into the interaction history, informing the next cycle.
- Iterative Refinement and Task Completion: This loop of reasoning, capability selection, execution, and observation continues iteratively. The process concludes when the agent determines the task is complete (often signaled by invoking a specific "completion" capability), a maximum number of turns is reached, or an external interruption is received.
2. Planning and Reflection: Structured Reasoning Capability
A critical element of II-Agent's advanced problem-solving ability is its dedicated mechanism for structured planning and reflective reasoning. This capability is conceptually aligned with Anthropic's "think" tool, which advocates for a discrete space for metacognition during complex tool-use scenarios [4]. Such explicit planning modules have also been identified as vital in high-performing agent architectures for tasks like software engineering [3].
This structured reasoning capability empowers the agent to:
- Decompose complex problems into smaller, actionable steps, enabling systematic progress through intricate tasks.
- Externalize its strategic intent by clearly articulating its internal reasoning process, making the logic behind its decisions transparent and reviewable.
- Think sequentially, progressing step by step, while remaining flexible enough to reframe the plan if new challenges or insights arise.
- Reflect on earlier decisions, with the ability to revisit and revise prior steps when new information suggests a better path forward.
- Explore alternative strategies, branching off from its original line of reasoning when needed, while keeping the main objective in sight.
- Remain open-ended and iterative, continuing to think even after reaching an initial conclusion if uncertainty remains or better solutions are possible.
- Form and test hypotheses, verifying outcomes against its chain of reasoning and repeating the process until it reaches a satisfactory solution.
Each invocation of this planning capability logs a structured "thought" within the agent's interaction history. This creates a transparent audit trail of the decision-making process, which is invaluable for debugging, understanding agent behavior, and facilitating iterative improvement of problem-solving strategies.
3. Execution Capabilities: A Versatile Toolkit
II-Agent is endowed with a rich set of capabilities, or "tools," that allow it to interact with its environment, process information, and generate diverse outputs:
- File System Operations: The agent can view, create, and modify files within its secure, designated workspace. Its editing capabilities are sophisticated, supporting precise string replacements and line-based insertions. A key feature is its ability to intelligently match and maintain existing code indentation styles when modifying files, which is crucial for preserving the integrity and readability of source code.
- Command Line Execution: The agent has access to a persistent shell environment, enabling it to execute arbitrary shell commands. This interaction is managed robustly (via pexpect or similar mechanisms). The system supports command filtering, allowing for transparent modification or wrapping of commands, for example, to redirect execution to a containerized environment. This provides a flexible and secure way to manage dependencies and execution contexts, a technique also noted for its utility in standardized agent evaluations [3].
- Web Interaction:
- Initial Information Retrieval: For rapid information gathering, the agent utilizes tools to perform web searches (e.g., via Tavily API, SerpAPI, FireCrawl) and extract primary textual content from specified URLs. If this extracted content is sufficient to complete the task, further browser actions are avoided, optimizing for speed and efficiency.
- **Advanced Browser Automation:**When a task requires more than just textual input, such as visual interpretation or webpage interaction, the II-Agent utilizes a set of advanced browser automation tools. These are built on [10], which leverages lmnr-ai/index [11] along with the vision capabilities of language models (e.g., Claude Sonnet 3.7 or GPT-4o), enabling the agent to:
- Navigate and manage browser sessions: Including navigating to URLs, creating, and switching between tabs.
- Simulate user interactions: Such as clicking elements, entering text in form fields, scrolling, and pressing keyboard keys.
- Capture and analyze browser state: After each action, a screenshot is taken and returned to the agent. The agent, using its vision capabilities, analyzes the screenshot to understand the page and determine the next action, like clicking a button or field.
- Task Finalization: A dedicated capability allows the agent to formally signal the completion of an assigned task and provide a consolidated final answer, summary, or set of deliverables.
- Specialized Capabilities: The agent's architecture is designed for extensibility and can incorporate specialized tools for various modalities. Current advanced capabilities include PDF text extraction (leveraging pymupdf), audio transcription and speech synthesis (via OpenAI models on Azure), image generation (using Google's Imagen 3 on Vertex AI), and video generation from text (via Google's Veo 2 on Vertex AI).
- Deep Research Integration: While Claude 3.7 Sonnet excels in coding and sequential planning, their ability to perform long complex reasoning and solve hard mathematical problems is still not as good. Hence, to further improve the ability of II-Agent, we extend II-Researcher [12] as a research tool that can be used to enhance the ability of II-Agent.
4. Context Management

Managing the LLM's limited contextual window effectively across potentially lengthy and complex interactions is paramount. II-Agent implements a sophisticated context management system to address this:
- Token Usage Estimation: The system employs a token-counting mechanism to approximate the size of the conversational history sent to the LLM. This typically involves heuristics (e.g., characters-to-token ratios for text) and specific calculations for rich media like images.
- Strategic Truncation: When the estimated token count approaches the LLM's operational budget, truncation strategies are applied:
- Standard Truncation: A baseline approach involves summarizing or eliding the content of older tool outputs or internal agent deliberations. This strategy prioritizes retaining the full fidelity of the most recent turns in the conversation, as these are often most relevant to the immediate next step.
- File-Based Archival for Large Outputs: A more advanced strategy is employed for capabilities that can produce exceptionally verbose outputs (such as the full textual content of a webpage). Instead of directly including this large data blob in the LLM's immediate context, the full content is archived to a file within the agent's dedicated workspace. The conversational history is then updated with a compact placeholder or reference marker (e.g., [Content saved to: <filename>]) pointing to this archived file. This allows the agent to "remember" that the information exists and can retrieve it by reading the file if explicitly needed in a later step, without continuously consuming a large portion of the LLM's active context window. This technique is particularly valuable for tasks involving extensive data processing or review, aligning with practices for managing large artifacts in complex software engineering workflows[3].
The context management system transparently logs the token savings achieved through these strategies, aiding in analyzing and optimizing the agent's conversational efficiency.
5. Real-time Communication and Interaction
II-Agent incorporates a real-time communication interface using WebSockets to facilitate interactive use cases. It is typically implemented with a framework like FastAPI.
- Each client connecting to the WebSocket server instantiates a dedicated and isolated agent instance. These instances operate within their secure workspaces, often mapped to unique subdirectories on the file system, ensuring that concurrent sessions do not interfere.
- The agent utilizes an internal message queue to stream significant operational events (such as the initiation of a thinking step, a tool invocation, the result of a tool execution, or browser state changes) back to the connected client. This enables a responsive user experience by providing real-time visibility into the agent's ongoing activities.
- The server architecture also typically includes API endpoints for auxiliary functions, such as allowing users to upload files directly into their specific agent's workspace, providing necessary input, or resources.
Benchmark:
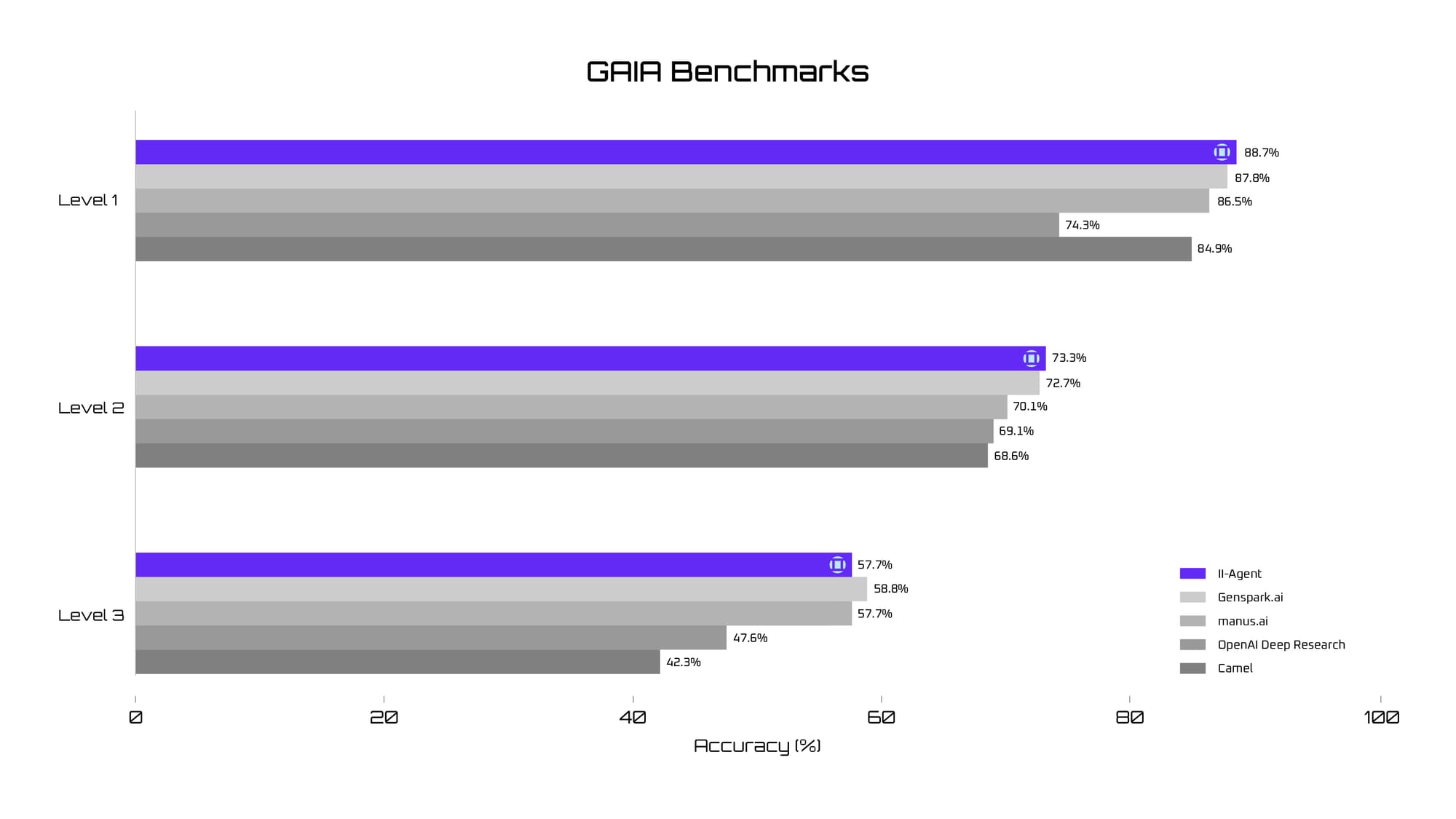
- Benchmarks: Our model is evaluated on theGAIA benchmark [7], designed to assess LLM-based agents operating within realistic scenarios. The GAIA benchmark tests agents' capabilities across multiple dimensions, including multimodal processing, tool utilization, and web searching, requiring varying autonomy and complexity.
- Evaluation Metrics: Following the GAIA benchmark, we adopt accuracy as our primary evaluation metric.
- Following Manus, OpenAI, we are also using the validation set for our benchmark [6]
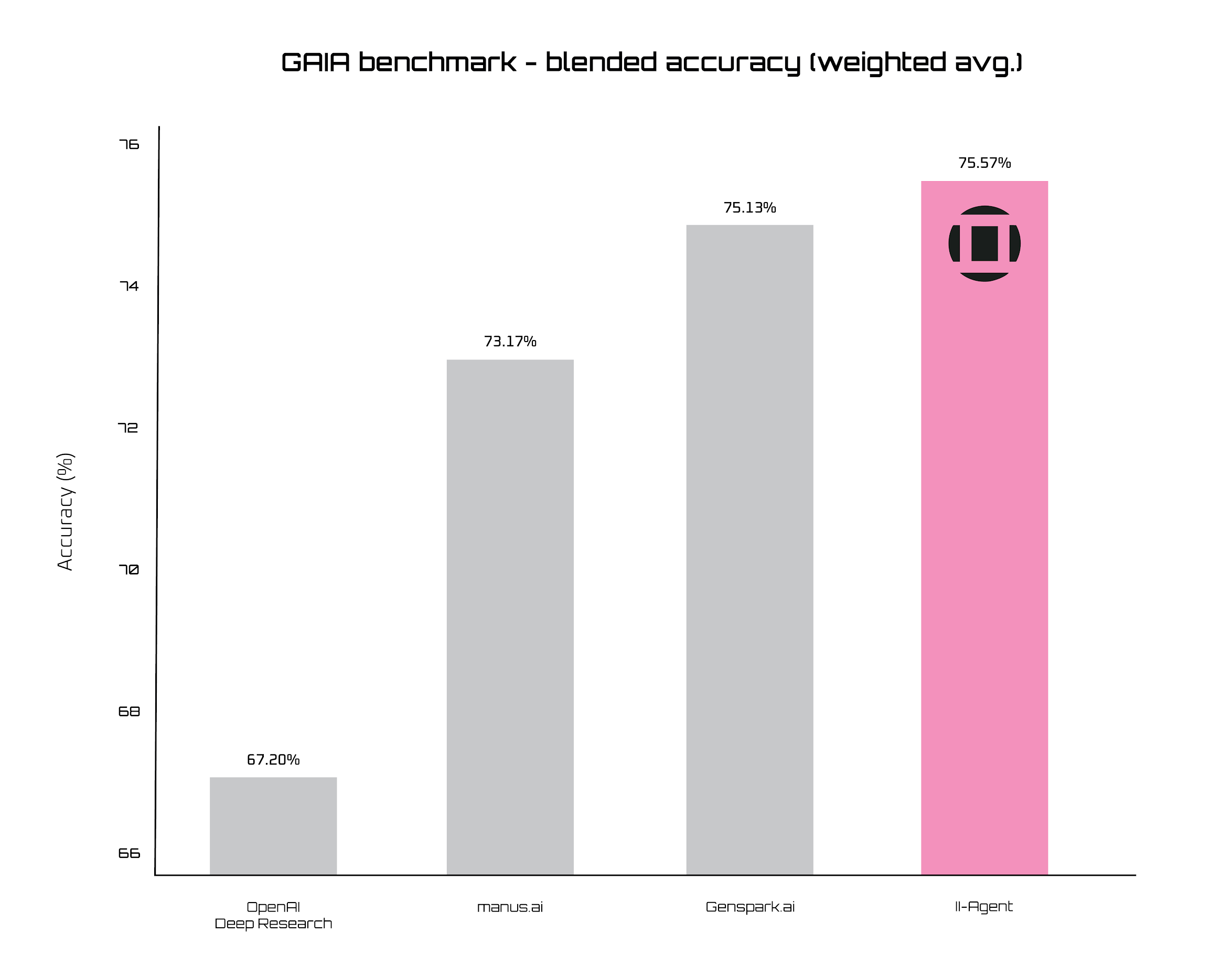
II-Agent Performance on GAIA:
GAIA Benchmark Issues:
Some GAIA tasks have errors, such as incorrect answers, outdated web references, or ambiguous phrasing. These are documented in our benchmark analysis to support fairer comparisons across models.
Wrong Annotations:
Several incorrect annotations were identified in the GAIA dataset, illustrated by the following examples [GAIA-Discussion]
Example 1 (Task ID: bec74516-02fc-48dc-b202-55e78d0e17cf):
Question:"What is the average number of pre-2020 works on the Open Researcher and Contributor Identification (ORCID) pages of the individuals identified in this file?"
However, the annotated metadata inaccurately considered publications prior to 2022:
-
"1. Opened each ORCID ID.
-
- Counted the works from pre-2022.
-
- Calculated the average: (54 + 61 + 1 + 16 + 0) / 5 = 132 / 5 = 26.4."
Example 2 (Task ID: e1fc63a2-da7a-432f-be78-7c4a95598703):
Question: "... Round your result to the nearest 1000 hours and do not use any comma separators if necessary."
The annotation, however, was incorrectly rounded to the nearest 100 hours:
-
"1. Researched Eliud Kipchoge’s marathon pace, determined as 4 minutes 37 seconds per mile.
-
- Converted this pace into fractional hours.
-
- Retrieved the lunar periapsis distance (225,623 miles).
-
- Multiplied the distance by pace to determine total hours, rounding to the nearest 100 hours."
The correct calculation is:
$225623 \text{ miles} \times \frac{(4\times60 + 37) \text{ minutes}}{60 \text{ minutes/hour}} = 62497571 \text{ seconds} \approx 17360 \text{ hours}$
When correctly rounded to the nearest 1000 hours, the answer should be 17000 hours, while the annotated "true answer" incorrectly states 17 hours.
Outdated Information / Website no longer accessible
Following the findings from the Camel team, several of their questions are based on outdated information:
Example (Task ID: ad2b4d70-9314-4fe6-bfbe-894a45f6055f)
Question: Eva Draconis has a personal website that can be accessed on her YouTube page. What is the meaning of the only symbol seen in the top banner that has a curved line that isn't a circle or a portion of a circle? Answer without punctuation.
The annotation instructs the agent to visit Eva Draconis's YouTube channel to verify her personal website URL listed in the about section. However, the channel currently contains no available information, and the referenced webpage (orionmindproject.com) is inaccessible.
Language Ambiguity Leads to Wrong Annotation
Example (Task ID: 8d46b8d6-b38a-47ff-ac74-cda14cf2d19b)
**Question:**What percentage of the total penguin population, according to the upper estimates on English Wikipedia at the end of 2012, is made up by the penguins in this file that don't live on Dream Island or have beaks longer than 42mm? Round to the nearest five decimal places.
Correct Interpretation: The question should logically be interpreted as counting penguins that simultaneously fulfill both conditions:
- They do not live on Dream Island AND
- They do not have beaks longer than 42 mm.
However, the original annotation incorrectly counted penguins by selecting those not on Dream Island with beaks longer than 42 mm, using:
Counted the penguins that are not on Dream Island with bills shorter than 42mm using COUNTIFS(C1:C345, ">42", B1:B345, "<>Dream") (132)
This approach resulted in an incorrect annotation. The correct annotation should have counted penguins that satisfy both conditions simultaneously, i.e., those not residing on Dream Island and having beak lengths of 42 mm or less.
Demo:
Conclusion
II-Agent is more than just a tool. It is a starting point for a broader shift toward open, agentic systems that empower individuals and institutions alike. Its design encourages experimentation, collaboration, and responsible AI development.
We are building toward a future where swarms of agents can work together across domains such as science, education, healthcare, and governance. These agents will form infrastructure that is interoperable, accountable, and community-driven.
Whether you are a researcher, engineer, educator, or policymaker, II-Agent is a foundation you can build on. The next chapter of intelligent systems will not be locked behind walls. It will be open to all. Let’s shape that future together.
Future Works
References:
- Monica. (2025). Manus AI [Computer software].https://manus.im/
- MainFunc. (2025). GenSpark AI [Computer software].https://www.genspark.ai/
- Augment Code. (2025). Augment SWE-bench Agent [Computer software]. GitHub. https://github.com/augmentcode/augment-swebench-agent
- Anthropic. (2025, March 20). The "think" tool: Enabling Claude to stop and think in complex tool use situations. Anthropic Engineering Blog.https://www.anthropic.com/engineering/claude-think-tool
- Hugging Face. (2025). Open Deep Research (smolagents/examples/open_deep_research) [Computer software]. GitHub. https://github.com/huggingface/smolagents/tree/main/examples/open_deep_research
- Roucher, A., Villanova del Moral, A., Noyan, M., Wolf, T., & Fourrier, C. (2025, February 4). Open-source DeepResearch – Freeing our search agents. Hugging Face. https://huggingface.co/blog/open-deep-research
- Mialon, G., Fourrier, C., Wolf, T., LeCun, Y., & Scialom, T. (2023, November). Gaia: a benchmark for general ai assistants. In The Twelfth International Conference on Learning Representations.
- Liang, X., Xiang, J., Yu, Z., Zhang, J., Hong, S., Fan, S., & Tang, X. (2025). OpenManus: An open-source framework for building general AI agents [Computer software]. Zenodo. https://doi.org/10.5281/zenodo.15186407
- Kortix AI Corp. (2025). Suna: Open Source Generalist AI Agent [Computer software]. GitHub. https://github.com/kortix-ai/suna
- lmnr-ai. (2025). Index: Open-source browser agent for autonomous web tasks [Computer software]. GitHub. https://github.com/lmnr-ai/index
- Microsoft. (2025). Playwright: Web testing and automation framework [Computer software]. GitHub. https://github.com/microsoft/playwright
- Intelligent Internet. (2025, March 28). II-Researcher. https://www.ii.inc/blog/post/ii-researcher