Featured Update: July 15th, 2025
What’s New in II-Commons Wave 2
Our second wave turns II-Commons from a pure knowledge-base toolkit into the backbone of a context-aware human-AI partnership.
Highlights:
- Wave 2 launch: Beyond just code. Two experimental applications and a scientific dataset ship today, signaling II-Commons expansion into a product series. Together, they build Procedural, Cognitive, Chronological, and Scientific context — rather than leaving users to reconstruct it themselves.
- Concrete artefacts, real workflows. The new releases act as reference implementations: you can run them locally, inspect how they use II-Commons indexes, and adapt them to your own projects.
- Building in public is the default. Code, design docs and manifestos are all under Apache-2.0 on GitHub; frequent repo updates and community pull-requests are explicitly encouraged.
- Mission reaffirmed: augment, don’t replace. Every addition is designed to sharpen human critical thinking and reverse the “cognitive slope” of context-poor AI chat.
- Roadmap unchanged, momentum up. Earlier goals—API services, desktop app, multimodal indexes—remain on track, now backed by live Wave 2 code.
Try the new tools, fork the repos, and help shape the next wave of open, context-rich intelligence.
Links:
Scroll down to read the original II-Commons blog from May 19th, 2025
Introducing II-Commons
Building an Accessible, Trustworthy, and Open Foundation for Intelligence
Introduction
The power of Artificial Intelligence is undeniable, yet much of its potential remains locked behind opaque systems or constrained by scattered, inaccessible data. This "black box" nature of many AI tools, coupled with data fragmentation, often hinders progress toward AI that is broadly beneficial and easily understood. To unlock a more open and reliable AI future, we need a new approach to how AI accesses and utilizes information. That is why we are developing II-Commons, a practical solution designed to build shared, large-scale knowledge bases. This will help create AI that is not only more capable, but also more transparent and equitable for all.
II-Commons, and its core component II-Knowledge, aim to enhance personal and organizational knowledge management, improve the usability and accuracy of AI agents, support model training and fine-tuning, and empower the research community.
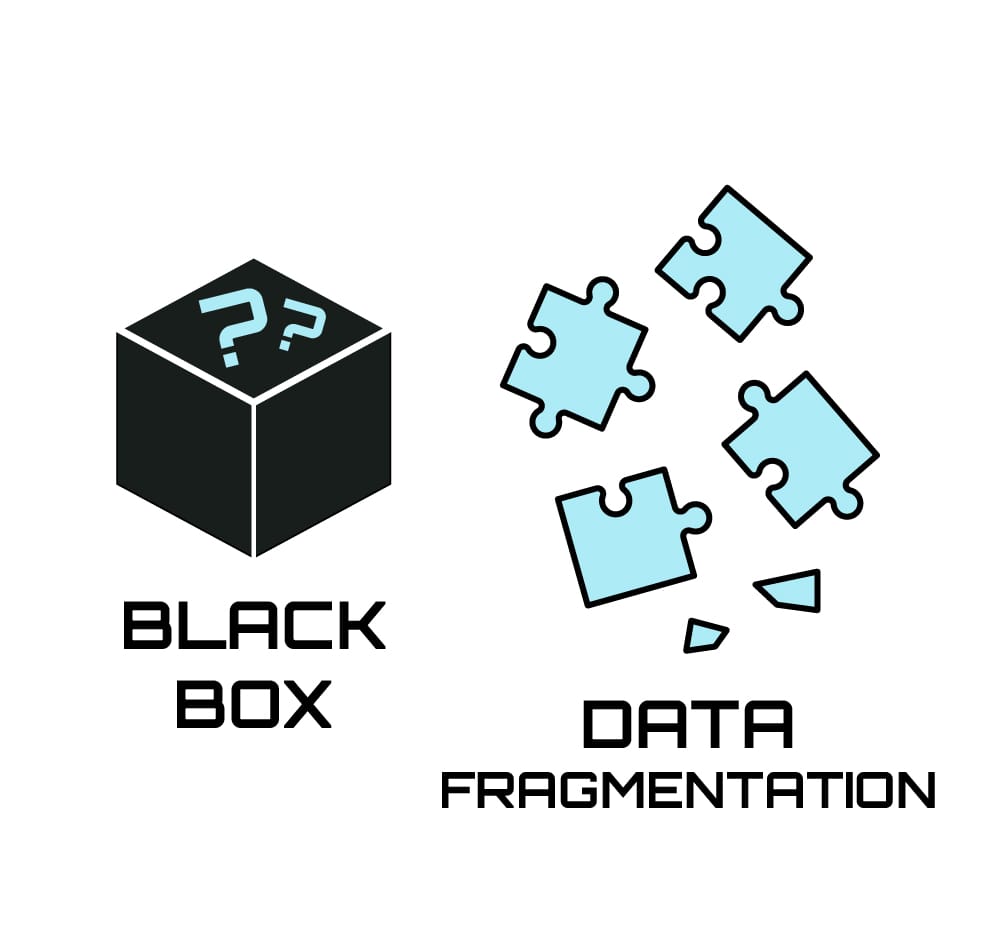
The Knowledge Gap in AI
Despite rapid progress in reasoning models and reinforcement learning, several challenges remain in AI's use of knowledge:
- Underutilization of Public Knowledge: While vast public data like Wikipedia exists, models often fail to access or use it reliably due to hallucinations or biases.
- Difficulty Leveraging Private Knowledge: Internal data such as research documents or chat logs often stays siloed due to privacy concerns and technical limitations.
- Lack of Data Sovereignty: Centralized platforms remove user control over their data and introduce risks related to transparency, privacy, and reliability.
- Information Overload from AI Outputs: Managing the explosion of AI-generated content—such as summaries, analyses, and code - is increasingly difficult without effective tools.
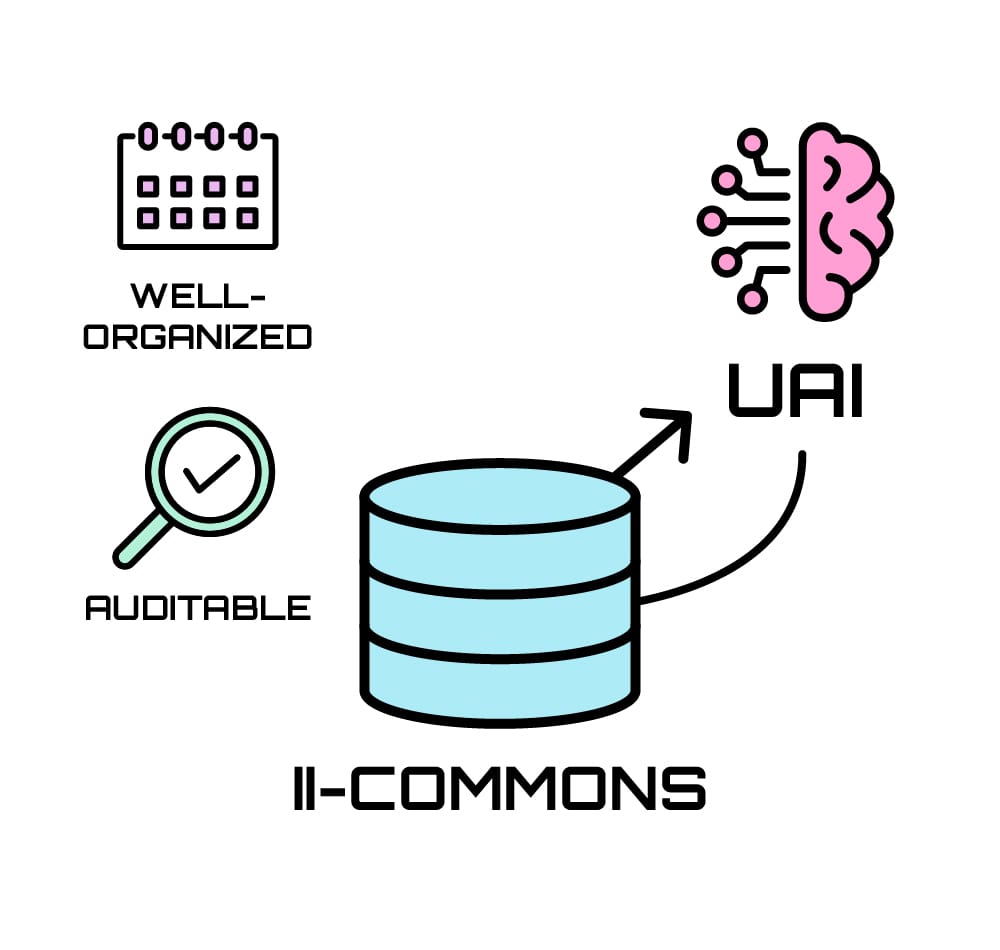
Our mission is to address these problems by offering an open, shared, and easy-to-use framework for building high-quality, multimodal knowledge bases that support both public and private use.
What is II-Commons and Why Is It Key?
II-Commons is a platform for collaboratively developing large, auditable, and efficient knowledge bases. It provides tools for distributed data handling, embedding computation, index creation, and search. Individuals and organizations can use it to build both public and private resources.
Why II-Commons Matters:
- Authentic and Accurate Multimodal Knowledge: II-Commons processes clearly sourced public datasets like Wikipedia and PD12M using high-performance open-licensed embedding models. Search capabilities include semantic, hybrid, and keyword matching across text and images.
- Supply Chain for Universal AI (UAI): A functional UAI requires large, structured, and verifiable datasets. II-Commons powers the creation of these datasets and pre-computed indexes, directly supporting open foundational models.
- Openness and Shared Innovation: With an Apache 2.0 license and fully open public datasets, II-Commons encourages participation from across the world. Its distributed architecture connects trusted contributor nodes to enable collaborative building while preserving data control.
- Improved AI Performance: Knowledge bases created with II-Commons improve AI grounding, search, and question-answering, resulting in better context understanding and more reliable outputs.
- Affordable and Accessible Technology: II-Commons is built on PostgreSQL with the VectorChord plugin (based on RaBitQ). It runs efficiently on everyday computers with 8GB RAM or inexpensive virtual machines, making it easy for anyone to participate.
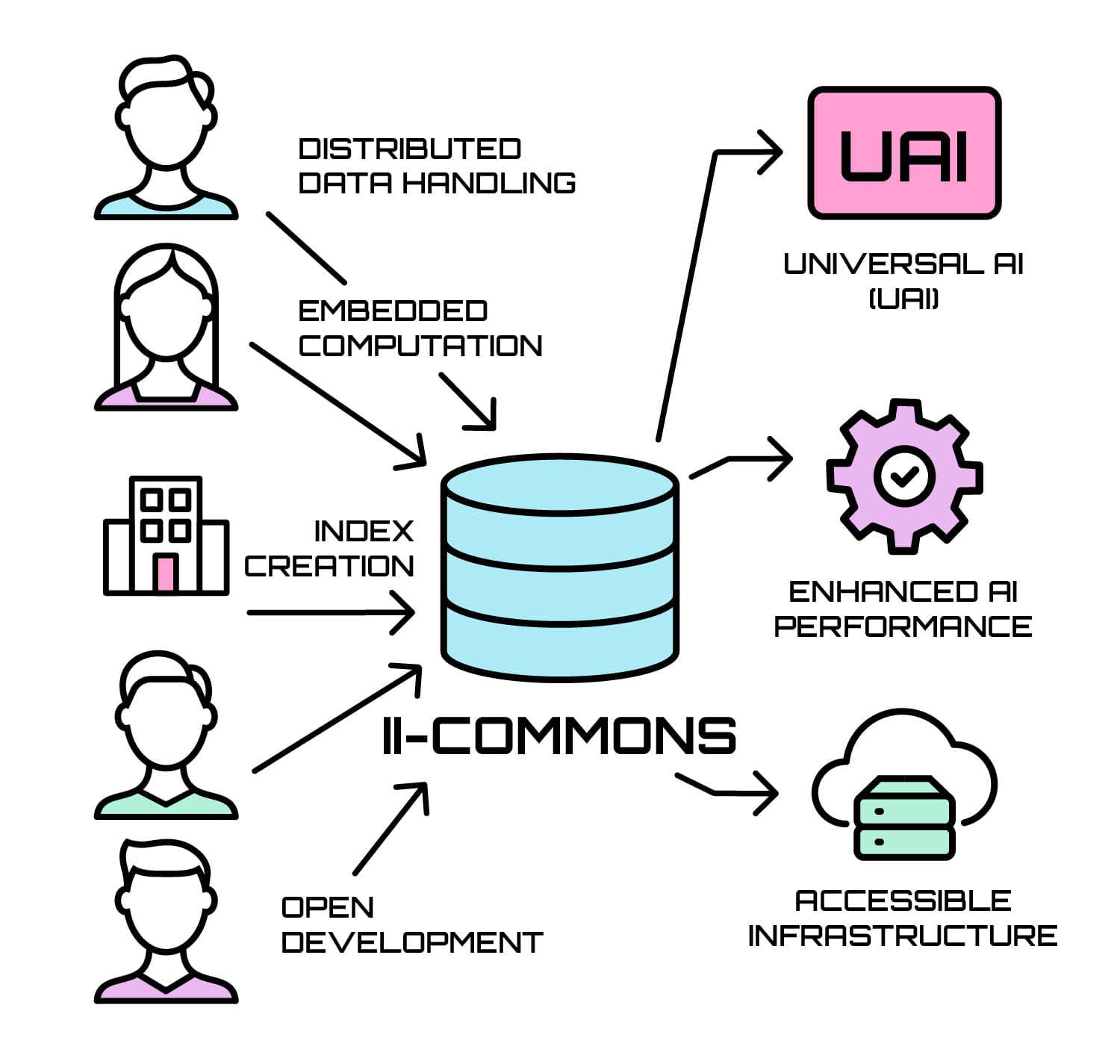
System Architecture
II-Commons is designed for simplicity, performance, and accessibility:
- Distributed Processing and Embedding: Nodes with virtual network connections work independently of cloud services, supporting trusted collaboration for building and computing knowledge.
- PostgreSQL and VectorChord Integration: Source data, metadata, and vector embeddings are stored and indexed using a lightweight, high-performance stack.
- Ready-to-Use Open Indexes:
- PD12M: A dataset of 12 million public domain images with siglip2 embeddings for image-text search.
- Wikipedia (English): Indexed using snowflake-arctic-embed-m-v2.0 for deep semantic search.
- API Examples Available: Users can create their own search services, RAG pipelines, or agents by building on our examples.
Performance Benchmarks
Tested on the MS MARCO v1.1 dataset with 8.8 million passages:
- Database Size: 48 GB including metadata and 768-dimensional embeddings
- Vector Index Size: 19 GB
- Search Results (NDCG@10, TREC DL 2019):
Model Type | MiniLM-L12 | BGE Re-ranker | Similarly |
BM25 | 0.302 | 0.418 | 0.415 |
Embedding Only | 0.661 | 0.712 | 0.700 |
Hybrid (80 percent Embedding / 20 percent BM25) | 0.598 | 0.723 | 0.726 |
Embedding Only with Zero BM25 | 0.661 | 0.733 | 0.723 |
These results show that II-Commons provides competitive and efficient search performance suitable for a wide range of use cases.
Why II-Commons Matters to You and Everyone
II-Commons offers broad benefits across technical and non-technical communities:
- Trustworthy and Transparent AI: Ensure that AI systems are built on knowledge that is auditable, reliable, and open, especially in critical domains such as healthcare and finance.
- Democratized Innovation: By providing access to open knowledge, II-Commons enables researchers and developers everywhere to contribute and build new tools.
- Better Information Management: Individuals and organizations can use II-Commons to organize their information more effectively and make better decisions.
- Infrastructure for Public Good: II-Commons supports Universal AI, or intelligence tools that serve education, public services, and science.
- Control Over Private Data: Organizations can build private knowledge bases that remain fully under their control, unlocking AI's benefits without sacrificing data sovereignty.
Getting Started with II-Commons
II-Commons supports a wide range of users:
- For Individuals: Build a cross-modal knowledge engine on your personal computer.
- For AI Developers: Use it for retrieval, grounding, or enhancement in local AI agents or RAG systems.
- For Model Trainers: Integrate with training pipelines to improve dataset quality and diversity.
- For Data Engineers: Build or extend data management platforms using II-Commons as a foundation.
- For Researchers: Filter data, run information retrieval experiments, and train custom models.
A Collaborative Approach to Knowledge Building
The future of knowledge infrastructure depends on collaboration. II-Commons enables shared knowledge creation by supporting distributed data collection, embedding, and retrieval. Communities, researchers, and individuals can all contribute to building and improving this ecosystem together.
What’s Next
Our development roadmap includes:
- Launching API services for shared datasets
- Automating configuration and performance tuning
- Simplifying setup and user experience
- Expanding with indexes for PDFs, videos, and audio
- Creating more AI-generated knowledge bases with public value
- Releasing a desktop version for everyday users
- Hosting a hub for downloading and sharing knowledge bases
- Staying aligned with the latest models and embedding tools
These updates will make II-Commons even more powerful as a foundation for open, distributed intelligence.
Conclusion
Creating an equitable, transparent, and beneficial AI ecosystem requires more than strong models. It requires a foundation of knowledge that is shared, trustworthy, and easy to build upon. II-Commons delivers that foundation. Whether you are building AI, managing your data, or conducting research, II-Commons gives you the tools to contribute to and benefit from collective intelligence.
Try It Now
- GitHub:https://github.com/Intelligent-Internet/ii-commons
- HuggingFace Download Page: https://huggingface.co/collections/Intelligent-Internet/ii-commons-682b2a3b108d6ea0a8b01763
- API Service & Demo Site: Coming Soon