TL;DR
Zenith in Brief
Long-running agents often fail not because they cannot make progress, but because they stop before the task is truly complete.
We tested five harness designs across eight long-horizon tasks to isolate the control mechanisms that matter: repeated gap-finding, revisable planning, independent verification, adaptive orchestration, and stopping discipline.
RALPH is the strongest simple baseline because it forces each new session to reopen the gap between the current project state and the original requirement. But RALPH is expensive and has no principled stopping rule.
Our Zenith method keeps the useful parts of repeated review while making the loop adaptive: the orchestrator dynamically allocates workers, testers, reusable skills, replanning, and stopping decisions.
In this study, Zenith achieved the best mean rank while using less than half of RALPH's per-task cost.
Read the full paper on GitHub.
Agents stop before the task is actually done
A long-running agent can look successful while still failing the task.
It builds something plausible. It runs the checks it chose for itself. It writes a confident summary. Then it stops while important requirements remain unmet.
We call this premature completion.
This failure is not usually about intelligence at a single step. The model may be capable of making progress. The problem is the control loop around the model: whether the system preserves state, reopens gaps, verifies progress independently, and knows when continued work is still worth the cost.
That matters because long-horizon agent work is becoming less like chat and more like project execution. Product builds, repository-scale implementation, optimization loops, and ML reproduction tasks all require an agent to maintain context over many attempts, recover from earlier mistakes, and handle delayed feedback.
A stronger model helps. But the harness around the model decides whether the system keeps looking for missing work or declares victory too early.
In this post, we study premature completion as a harness-design problem. We tested five harnesses across eight long-horizon tasks. The result is a ladder: each harness fixes one failure mode and exposes the next.
The same bottleneck shows up across the recent agent literature. METR frames it as a task-completion time horizon; the length of time an agent can reliably complete a task. Systems like FutureHouse’s Robin, Google’s AI co-scientist, and Google DeepMind’s AlphaEvolve all extend agents past a single session: they require state, gap-finding, error recovery, and self-improvement. Those are the same ingredients our harness study isolates.
The core question is: What harness mechanisms actually help long-running agents finish the task rather than merely make progress?
To investigate solutions to these issues for long-running tasks, we tested five harness designs across eight long-horizon tasks. The result was a ladder: each harness exposed a failure mode that the next harness had to fix.
Long-horizon performance is a control problem
Before comparing harnesses, it helps to separate the model from the control loop around the model.
The model determines what can be done inside a session. The harness determines how sessions are arranged, how state is preserved, how progress is checked, and when the system should continue or stop.
The important mechanisms are:
Control Table
Core Control Mechanisms
| Control mechanism | Question it answers | Why it matters |
|---|---|---|
| State preservation | What has already been built, tested, and learned? | Prevents each session from rediscovering the same context from scratch. |
| Gap-finding | What is still missing relative to the original requirement? | Counteracts premature completion and keeps the task anchored to the user's goal. |
| Revisable planning | Should the plan change now that the project state has changed? | Avoids executing stale upfront plans after the worker has learned new constraints. |
| Independent verification | Did the system actually satisfy the requirement, or did the worker only say it did? | Prevents worker self-reports from becoming the source of truth. |
| Stopping discipline | Is another pass likely to improve the result enough to justify the cost? | Turns open-ended iteration into a cost-aware control decision. |
These mechanisms define the harness ladder.
One session has none of them. RALPH adds repeated gap-finding. Plan-RALPH adds planning, but in a static form. Milestone-RALPH makes planning more local and adds independent verification. Zenith adds adaptive orchestration and stopping discipline.
The harness ladder
We compare five harnesses:
- One-session
- RALPH
- Plan-RALPH
- Milestone-RALPH
- Zenith
Each harness keeps most of the previous structure and adds one new control mechanism.
The point of the ladder is not just to rank systems. It is to expose the failure mode that appears when a specific control mechanism is missing.
One session: the cheapest baseline
Send the full task to a single agent session (e.g., Codex or Claude Code) and let it run end-to-end. No planning layer, no outer loop, no independent tester. The agent decides when it is done.
The failure mode shows up immediately. On long-horizon work, the agent ships a plausible draft, runs the checks it chose, writes a confident summary, and stops while real requirements are still missing. We call this premature completion. It is the reason every harness in this post exists.
RALPH: repeated gap-finding
RALPH runs many sessions instead of one. Each new session reopens the original requirement and runs against the project state left by the previous session, with a single instruction: find the gap between the current state and the user’s requirement, and close it. The next iteration starts from the new state and repeats.
This is the simplest possible cure for premature completion and on every task we measured, it works. But each session pays to rediscover the next gap from scratch, and the loop has no internal stopping rule. We stop by a fixed iteration or budget cutoff.
Plan-RALPH: plan once, then check items off
Inspired by Anthropic’s effective harnesses for long-running agents writeup, Plan-RALPH adds a fixed work list before execution begins. A planner reads the requirement and writes the features the harness should build. Each session picks one unfinished item, implements it, and marks it done.
The plan reduces per-session rediscovery cost. The problem is that the plan is written before the executor learns anything, and “done” labels are produced by the same worker who did the work. The list goes stale, and false-done labels become the harness’s truth.
Milestone-RALPH: plan late, test independently
Milestone-RALPH keeps planning, but moves it. Only the milestone-level strategy is fixed upfront. Detailed task lists are planned when each milestone begins, conditioned on the project state that actually exists at that moment. And a milestone cannot transition because the worker says it is done; it has to pass an independent tester. Tester failures become new milestone-local tasks.
This is the first place in the ladder where testing, not just iterating or planning, starts to pay off as its own axis. But the worker, tester, and skill set are still mostly fixed, and the loop can stall when the next step isn't “add another feature.”
Introducing Zenith: adaptive orchestration
Zenith keeps the milestone loop, but makes the control layer adaptive. An LLM orchestrator owns the plan, worker definitions, tester definitions, reusable skills, and stopping decisions.
Planning is deeper. Workers are designed on a per-task basis at runtime, not pulled from a generic library. Testing runs in multiple layers: a validator for build, test, typecheck, lint, and per-feature review subagents, plus a user-testing validator that drives the real surface. A milestone is sealed only after both layers pass.
Recurring patterns are lifted into reusable skills, so later sessions do not have to relearn them. At every boundary, the orchestrator decides one of the following: continue, replan, add a worker, add a tester, synthesize a skill, reset strategy, move to the next milestone, or stop. The harness enforces the protocol; the orchestrator decides the shape of work inside that protocol.
Example
A concrete walk-through
Consider a product-build task like Angry Birds.
A normal build/test loop may pass lint, compile successfully, and still fail the actual product requirement. The game may run, but the slingshot animation may skip frames, the block layout may not match the reference, or the level may not satisfy the fidelity constraints in the spec.
In a one-session run, the agent may stop after the build passes.
In RALPH, a later session may rediscover that the visual behavior is wrong and attempt to fix it.
In Zenith, the orchestrator can change the structure of the work.
It may start with a gameplay worker, a UI worker, and a validator that runs build, lint, typecheck, and tests. After the first playable build exists, the orchestrator can add a browser-based user-testing validator that opens the real game, captures screenshots, and checks the rendered behavior against the spec.
If the user-testing validator repeatedly finds level-fidelity failures, the orchestrator does not have to keep asking the same worker to try again blindly. It can synthesize a reusable “spec-to-visual-checklist” skill and require future workers to apply it before marking a milestone complete.
If a milestone’s verifier keeps failing for the same root cause across several rounds, Zenith can replan or escalate instead of continuing the same loop.
That is the difference between iteration and orchestration.
“What is still missing?”
“What kind of work, verification, or strategy change is needed now?”
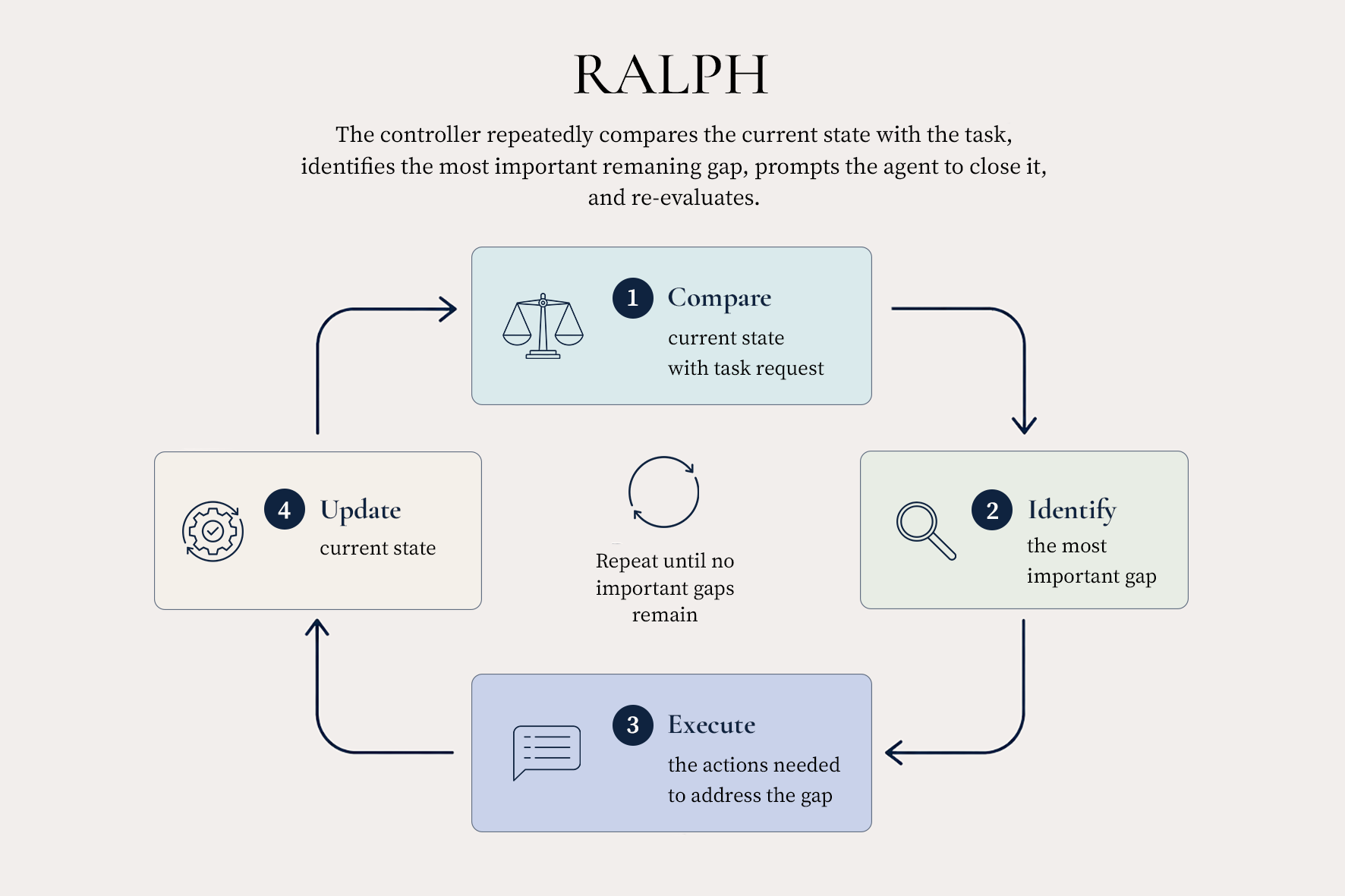
(a) RALPH repeated gap-finding.

(b) Plan-RALPH fixed work list.
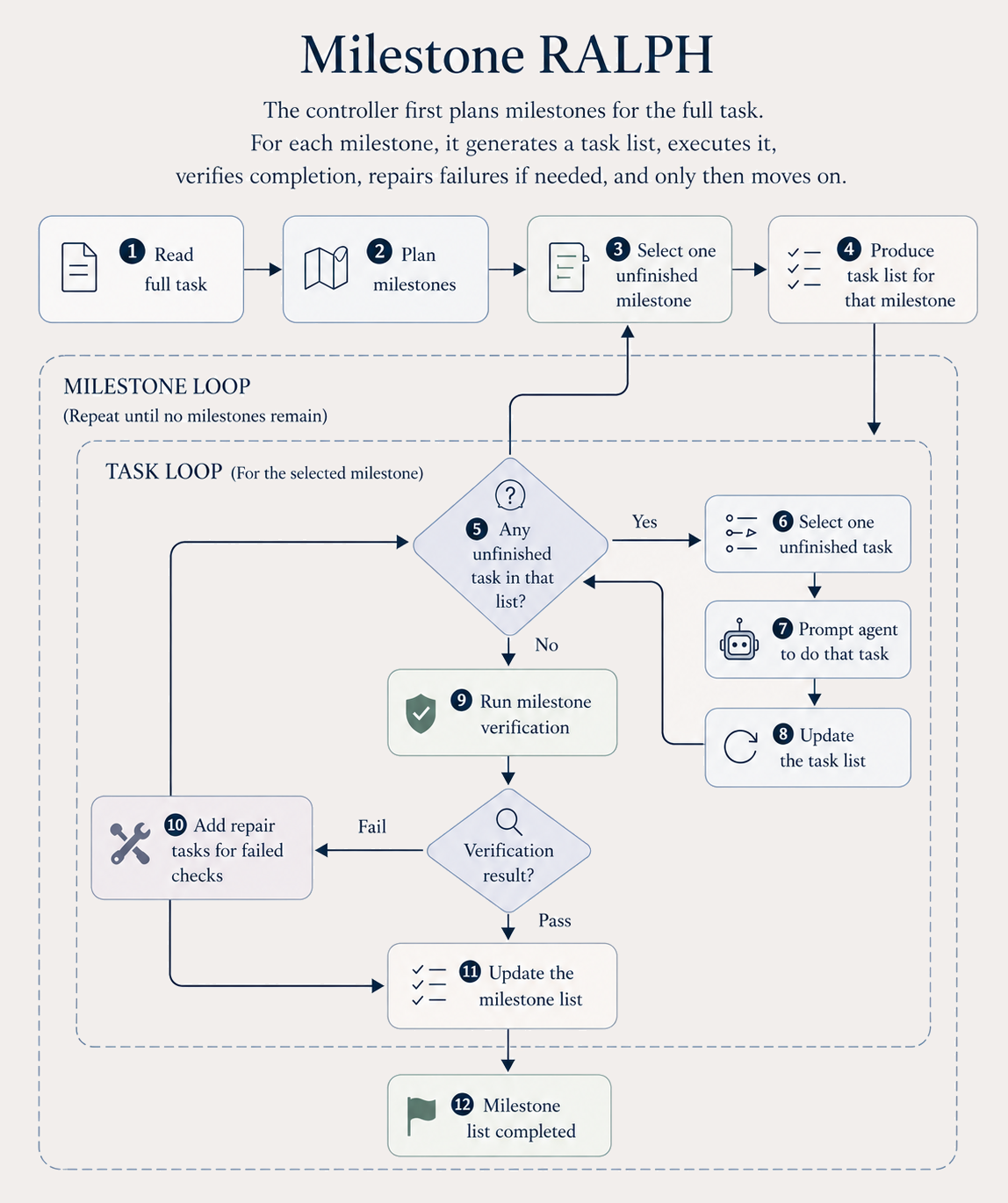
(c) Milestone-RALPH milestone planning + independent testing.
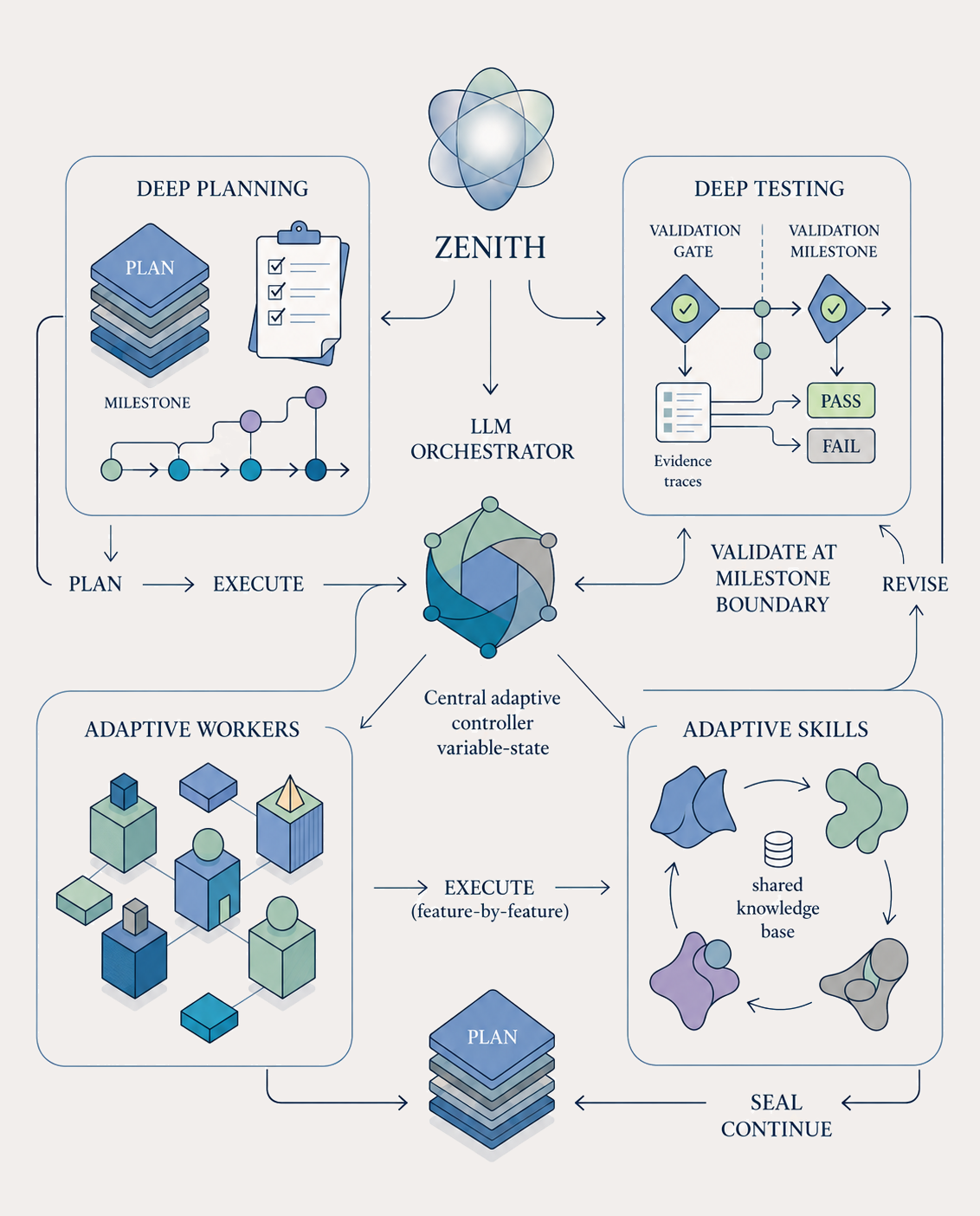
(d) Zenith adaptive orchestrator.
Figure 1. The four control flows. Each harness keeps most of the previous structure and adds one new mechanism.
Evaluation setup
We evaluate across eight long-horizon tasks.
Benchmark Tasks
Evaluation Task Suite
| Family | Task | What the agent must do | Source |
|---|---|---|---|
| Product builds | Angry Birds | Browser game from a multi-file spec with level-fidelity constraints. | Internal |
| Product builds | Cowork | Desktop app around a real agent SDK with permissions, browser use, MCP, and plugins. | Internal |
| Repository-scale | Ydata Profiling | Implement a substantial software library from a broad feature spec. | NL2Repo-Bench |
| Repository-scale | Git To Zig | Reimplement Git in Zig as a drop-in replacement. | Frontier-SWE |
| Optimization | Chess Engine | Iteratively improve a chess engine to maximize an external Elo. | Hive-Chess |
| ML/Research | Web Traffic Forecasting | Forecasting pipeline for large-scale time series under a fixed submission attempt. | AIRS-Bench |
| ML/Research | Paperbench Rice | Reproduce a research paper’s methods, experiments, and outputs from its rubric. | Paper-Bench |
| ML/Research | Paperbench Ftrl | Reproduce a research paper’s methods, experiments, and outputs from its rubric. | Paper-Bench |
Models, cost, and scoring. All our experiments are based on GPT-5.4 XHigh and Opus-4.6 Max Effort; cost is model inference spend in US dollars, and RALPH is capped by a fixed iteration count or a maximum time allowance. Because raw scores are not comparable across families, we report mean rank: for each task, the five methods are ranked 1 (best) to 5 (worst, direction-corrected) after averaging the Claude and Codex runs, then the ranks are averaged across the eight tasks. Wins count the best observed run per project.
Results
In our runs, Zenith won five of eight projects. RALPH won three. One-session won none.
Zenith achieved the best mean rank, while using less than half of RALPH’s per-task cost.
The result is consistent with the failure-mode reading above: harnesses that can reopen gaps, revise plans, verify independently, and adapt the shape of work beat harnesses that cannot.
.png)
Figure 2. Mean rank and mean cost per task. Three controllers sit on the rank–cost Pareto frontier (One-session, Plan-RALPH, Zenith); the other two are dominated by Zenith on both axes in this study.
Three controllers sit on the rank-cost Pareto frontier: One-session, Plan-RALPH, and Zenith. The other two are dominated by Zenith on both axes in this study.
Plan-RALPH sits on the frontier only because it is the cheapest harness above the one-session baseline. The frontier rewards any method that wins on at least one axis. Read its position as “cheapest,” not “best.”
The key result is not simply that Zenith spent less. It is that Zenith allocated work more effectively.
RALPH spends heavily on repeated gap-finding. Zenith preserves repeated review, but makes each pass more targeted through adaptive workers, validators, skills, replanning, and stopping decisions.
What the results mean
Iteration is the biggest first-order effect
Even a planless outer loop like RALPH improved over One-session on every task we measured. Forcing the agent to keep asking “what is still missing?” after each session is enough to dissolve premature completion the simplest cure beats no cure, uniformly.
Static planning is worse than revisable planning
In this evaluation, Plan-RALPH underperformed RALPH on every external task despite its extra planning layer. The reading is not that planning is bad. It is that a static upfront plan can become a liability on long-horizon work: it locks in early-stage assumptions about what to build and in what order, and the iterative loop then spends its budget executing a frozen blueprint rather than closing the gaps that actually matter. The planning step has to remain revisable as the executor learns.
Verification is a separate axis of progress
Milestone-RALPH recovers most of what static planning lost not by adding more planning, but by letting an independent tester decide when a milestone is done. Plan-RALPH’s worker self-reports were the bottleneck, not the plan itself. Once the harness can no longer confuse “a worker said done” with “the original requirement is satisfied,” progress becomes more durable.
Adaptive orchestration improved the cost-quality tradeoff
Zenith achieved the best mean rank in this study at less than half the per-task cost of RALPH, and improved the aggregate rank and cost profile over Milestone-RALPH while reducing repeated rediscovery work. What the system spends seems to matter more than how much on these tasks. The per-task table is the most honest read: Zenith and RALPH each dominate a complementary slice of the task space.
RALPH as test-time scaling for harnesses
RALPH is hard to beat because it behaves like test-time scaling for harnesses.
In language-model test-time compute scaling, the system spends additional inference on a static prompt, often through sampling, search, or verification.
RALPH spends additional inference on an evolving project state.
The unit of scaling is not “another answer.” It is “another session against the current artifact.”
On Git To Zig, for example, we tracked the score moving from 0.16 at iteration 1 to 0.27 at iteration 36, with plateaus, regressions, and sudden jumps along the way.
.png)
Figure 3. Per-iteration RALPH scores across three tasks. Late iterations keep buying score, with diminishing returns and no clean plateau.
Late iterations keep buying score, with diminishing returns and no clean plateau.
This explains both RALPH’s strength and its weakness.
More passes can still buy real progress. Early iterations close obvious gaps. Later iterations still find real issues, but each issue is harder to discover.
The curve does not provide a clean stopping signal. A rising or oscillating score means more work may still matter, not that more work is worth the cost.
That is exactly why later harnesses try to preserve repeated review while making each pass more targeted.
Summary
Takeaways
Long-horizon agent performance is not just a model problem. It is a control problem.
The simplest useful control loop is repeated gap-finding: force the agent to reopen the distance between the current state and the original requirement. RALPH shows that this works, but also shows the cost of brute-force iteration.
Planning only helps when it remains revisable.
Independent verification matters more than another planning layer. Milestone-level testing recovers most of what static planning lost.
Zenith combines those lessons into an adaptive harness: keep reopening gaps, but spend each pass more deliberately.
References
References
METR. Task-Completion Time Horizons of Frontier AI Models.
metr.orgFutureHouse. Demonstrating end-to-end scientific discovery with Robin, a multi-agent system.
futurehouse.orgGoogle Research. Accelerating scientific breakthroughs with an AI co-scientist.
research.googleGoogle DeepMind. AlphaEvolve: A Gemini-powered coding agent for designing advanced algorithms.
deepmind.googleAnthropic. Effective harnesses for long-running agents.
anthropic.comCharlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. arXiv preprint 2408.03314.
arxiv.orgJingzhe Ding et al. NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents. arXiv preprint 2512.12730.
arxiv.orgFrontierSWE. Git to Zig.
frontierswe.comMeta FAIR. AIRS-Bench: Long-Horizon Tasks for AI Research Science Agents.
github.comOpenAI. PaperBench: Evaluating AI's Ability to Replicate AI Research.
openai.com
We are planning to open-source Zenith soon. Create an II-Account to stay up to date.