TL;DR
Bottom line up front
Zenith is our long-running agent harness. Point it at a hard, long-running engineering task, and it builds a harness tailored to that task, runs the work, and tests it to the finish.
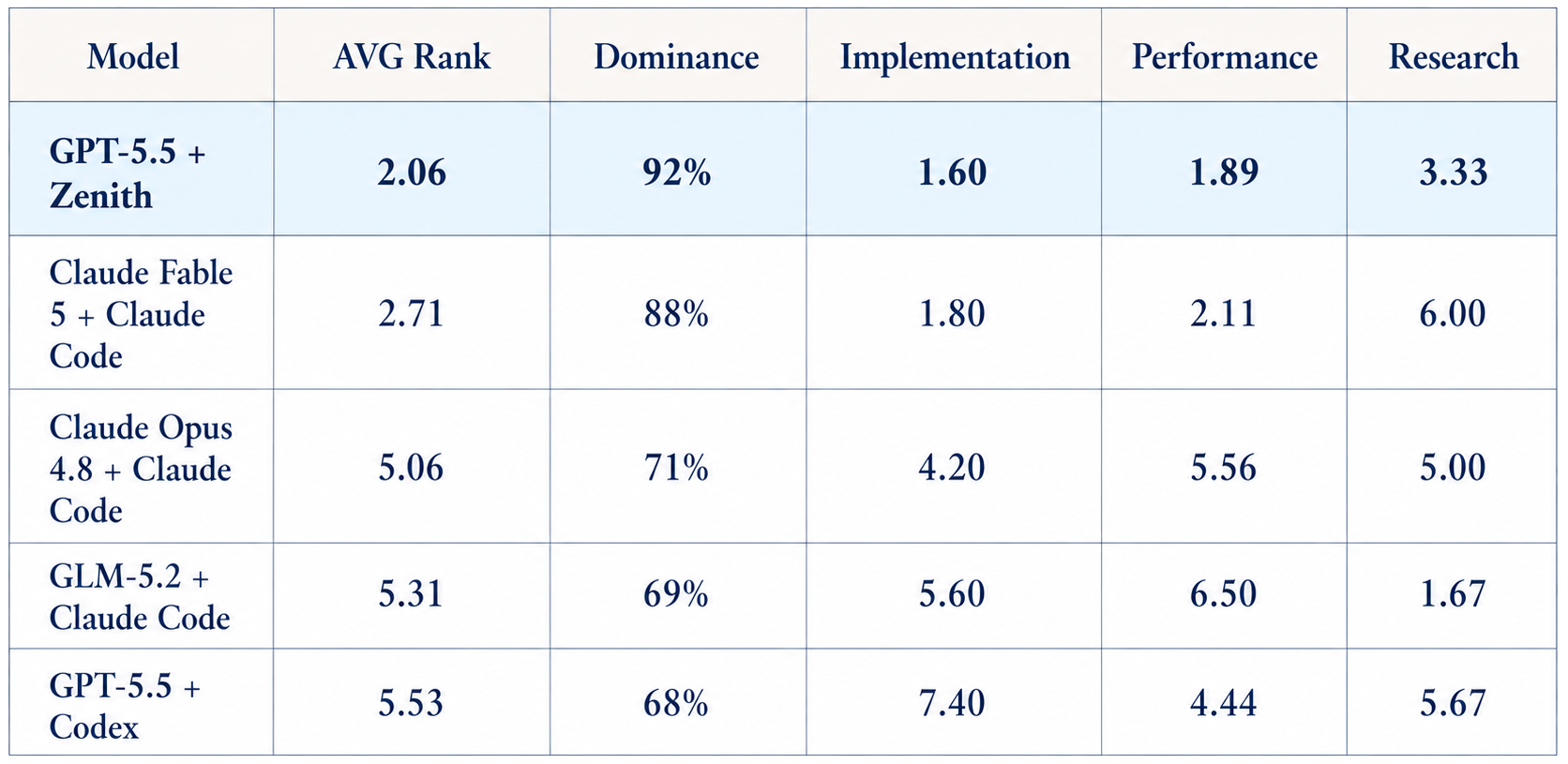
On Frontier SWE, seventeen of the hardest public long-horizon software-engineering tasks we know of, Zenith took GPT-5.5 from 5th place to 1st, ahead of Claude Fable, by building the right harness around the model instead of swapping in a bigger one.
That matters now because the strongest models are increasingly hard to reach. Fable 5's access was suspended under a US export-control directive and remains gated; GPT-5.6 launched as a limited preview for a small group of trusted partners. The system around the model is the part that builders can still own and improve.
Two ideas make long-running agents work: Zenith keeps the agent planning, testing, and improving across many sessions, while Meta-Zenith continuously learns how to build the right Zenith harness from feedback on real collected tasks.
Harness > Model for frontier performance
When an agent stalls on a hard, long-running task, the reflex is to reach for a stronger model. Zenith takes the other path. The model defines what's possible within a single session; the harness around it determines how sessions are arranged, how state is carried across them, how progress is checked, and when to stop. That is the part Zenith improves. Point Zenith at the task, and it builds a harness shaped to it, then drives the work to completion, testing as it goes. On Frontier SWE, the hardest long-horizon software-engineering benchmark we know of, that approach lifted GPT-5.5 to the top, past Claude Fable.
Zenith is the harness that keeps the agent working, testing, and improving over the long run. Meta-Zenith is how we generate the right Zenith for a new task.
And right now, reaching for a bigger model often isn't an option. Claude Fable 5, the model atop the public Frontier SWE board, had its access suspended under a US export-control directive and is still restricted to government-approved channels. OpenAI's GPT-5.6 Sol launched as a limited preview for a small group of trusted partners. When the strongest models are gated like this, the system around the one you can run is where your leverage is.
Fifth to first on Frontier SWE
Frontier SWE, built by Proximal, is not a normal coding benchmark. Its seventeen tasks are ultra-long-horizon: agents get twenty hours per task, and even so, most barely make progress. Prime Intellect, which hosts the benchmark on its EnvironmentsHub, reports that agents run about eleven hours per task on average and fail to solve almost all of them.
We ran the full suite with Zenith and scored it the same way Proximal scores the public leaderboard. By mean@5 the result lands first, at 2.06 average rank, with 92% dominance. The same GPT-5.5 model on its default Codex harness sits fifth, at 5.53. The benchmark, the trial budget, and the base model stayed the same. The only thing that changed was the control loop around the model.
Everything needed to check it is going in the release: task configs, model and version settings, per-run budgets, run logs, evaluator outputs, and the full results with cost, token, and runtime summaries.
The gap between harnesses is widest on implementation, the longest-horizon work on the benchmark. GPT-5.5 under Codex ranks 7.40 there. With Zenith, it ranks 1.60, ahead of every other entry, including Fable. That is the result we care about most, because Anthropic's own launch notes say the longer and more complex the task, the larger Fable's lead grows.
Implementation is also where the benchmark exposes the failure mode that Zenith exists to fix. Proximal found that on almost every task, models submit early, long before the time limit, not because they give up but out of overconfidence: the tests they write for themselves are superficial enough to let a wrong solution look right. The agent declares victory while the Git test suite still fails to decompress pack files, or while the kernel it just "optimized" is still slower than the reference on the shapes that matter. Independent, evidence-traced testing is the part of the harness that catches this, and it is what separates 7.40 from 1.60.

From a sketch to a harness, and continuous improvement
The first Zenith harness was built by hand. We manually wrote the system prompts, default skills, worker definitions, validation rules, and orchestration logic. To get there, we studied five harness designs across eight long-horizon tasks and isolated the control mechanisms that consistently mattered: repeated gap-finding, revisable planning, independent verification, adaptive orchestration, and disciplined stopping. We then combined these mechanisms into a single adaptive system that achieved the best mean rank while using less than half the cost of the brute-force baseline. The improvement came not from spending more compute, but from allocating work more intelligently.
However, scaling this process by hand does not work. Each new task family requires different worker roles, validation strategies, milestone decompositions, acceptance checks, and stopping policies. A harness that works well for one class of long-running software tasks may not transfer cleanly to another. Manually redesigning Zenith for every new task type would quickly become the bottleneck.
Meta-Zenith automates this construction process.
Given a simplified Orchestrator–Worker multi-agent sketch, a task specification, and feedback from the training loop, Meta-Zenith produces a fully configured Zenith harness. The process mirrors Zenith's own execution loop, but operates one level higher. Instead of executing implementation decisions against a codebase, Meta-Zenith executes harness-design decisions against the task specification.
The resulting harness includes the system prompts and default skills for the orchestrator and workers across each phase, including:
- Contract: the task's goals, acceptance criteria, and constraints
- Milestone graph: ordered by dependency and test coverage
- Worker specs: task-specific roles, prompts, tools, and skills
- Validator specs: build gates and fidelity (acceptance) checks
- Skill seeds: reusable patterns likely to recur
- Stop/replan policy: when to continue, revise, add workers, or stop
To train Meta-Zenith, we continuously collect our own daily engineering and research tasks and run the harness-construction loop over this internal task stream. This gives Meta-Zenith a steady source of realistic long-horizon tasks while keeping the optimization process separate from the benchmark itself.
The final Frontier SWE evaluation used finalized Zenith harnesses. The result should therefore be understood as a test of the completed harness design, not as task-by-task manual tuning against the benchmark.
More details on Meta-Zenith and open-source releases will be shared soon.
What Meta-Zenith builds: four subsystems, one orchestrator
After the training phase, Meta-Zenith produces a completed Zenith harness. Four subsystems run under one orchestrator that decides the next action at every boundary.
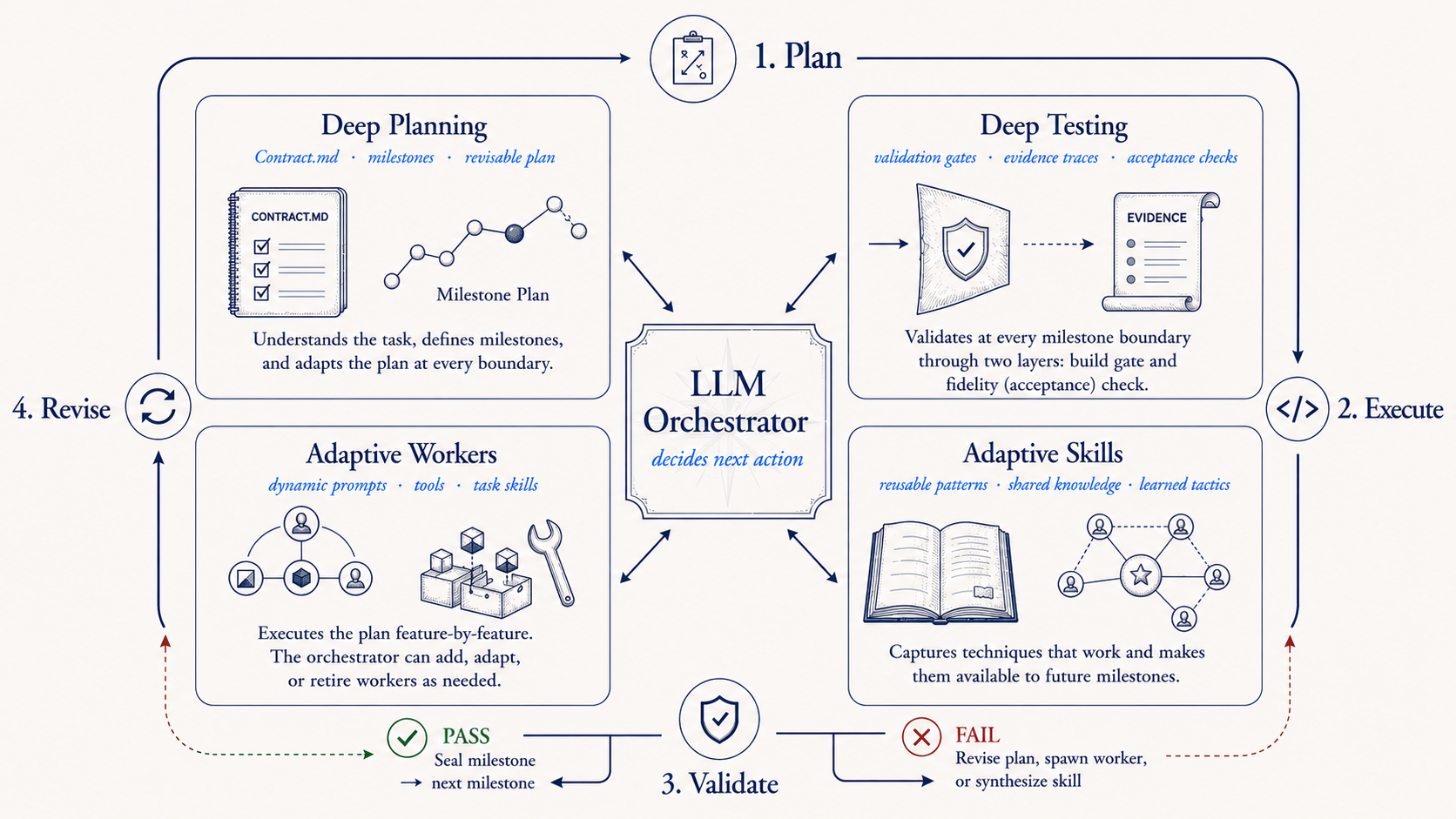
Deep Planning reads the task specification and produces a milestone-level strategy that revises at each boundary. When the executor discovers that Zig's allocator model breaks an assumption the plan made about memory management, the orchestrator replans rather than continuing to execute a blueprint that no longer fits.
Adaptive Workers execute the plan feature-by-feature, designed per task at construction time. The orchestrator can spawn a new worker when a milestone needs a capability the existing workers lack, or retire one that has finished its scope.
Deep Testing validates at every milestone boundary through two layers: a validation gate that runs build, test, typecheck, and lint, and a validation milestone that runs evidence-traced review against the task's acceptance criteria. A milestone seals only when both pass. When the fidelity validator finds that the video pipeline produces correct frames on two workloads but black output on the third, that finding becomes a new task, not a retry of the old one.
Adaptive Skills capture techniques that worked and register them for later milestones. When a worker discovers a pattern for debugging Zig's comptime evaluation failures, the orchestrator lifts it into a reusable skill. The next milestone that hits a compile-time error gets the skill automatically, without rediscovering the approach from scratch.
The harness enforces the protocol; the orchestrator decides the shape of work within it. At each boundary, it chooses whether to continue, replan, add a worker, add a tester, synthesize a skill, reset strategy, advance, or stop.
The improvement is adaptive, not recursive
Zenith adapts its workers, testers, skills, and strategy during a run, so it is tempting to call this "self-improvement." But recursive self-improvement means something more specific: a system modifying the mechanism by which it improves, so each enhancement makes the next one easier. Agents rewriting their own codebases. Discovery pipelines scheduling their own retraining. Demis Hassabis described the open question at WEF 2026 as whether that loop can close without a human in it; Jack Clark has put 60% odds on it happening by the end of 2028.
We call what Zenith does adaptive self-improvement. The model weights are frozen. The agent does not rewrite its own code. What changes during a run is the shape of work: which workers exist, what testing layers are active, what skills have been learned, and how the plan is structured. Later milestones benefit from earlier learning. The improvement is real, but it happens at the level of task strategy rather than system architecture, which makes it legible: you can read the orchestrator's decision trace, replay it, and understand why a specific skill was synthesized or a worker added at a specific boundary.
Point it at a hard task
AI agents can build compilers, optimize rendering pipelines, and train models against hidden benchmarks. The capability is here. What you cannot count on is access to the strongest model, now that the most capable ones are mediated by export controls and limited previews. When access is scarce, an open agent that improves the control loop around the model is how you recover frontier performance with a model you can actually run.
That is the world Zenith is built for. Hand it a hard task and a short sketch of the approach, and it builds the harness, runs the work, and tests it to the finish, carrying a model you can run to the top of a benchmark the strongest models were built for.
You can find the code for Zenith in our open source repository. The Frontier SWE configurations will be published alongside this post.
Intelligent Internet builds infrastructure for long-running agents.
The original Zenith technical report is on GitHub; the companion post on harness design is on ii.inc.